About me

Naresh Kumar Devulapally
Google Scholar | LinkedIn | Github | CV
I am a Computer Science Ph.D. candidate (Chair's Fellowship) with research interests in Multimodal Machine Learning, Representation Learning, and Graph Embeddings. My research advised by Dr. Junsong Yuan and Dr. Sreyasee Das Bhattacharjee at The Visual Computing Lab in the Department of Computer Science at the University at Buffalo, SUNY. My recent (first-author) works on Multimodal Machine Learning are published at ACM Multimedia 2023 (∼25% acceptance rate), ICME 2024, BigMM 2023 and so on.
Research Updates
Spring 2024:
- 🎉 One Paper on Multimodal Machine Learning, accepted at ICME 2024.
- Graduate Teaching Assistant @ (CSE 560) Data Models and Query Languages course at UB.
Fall 2023:
- 🎉 One Paper on Adaptive Fusion for Multimodal ML models, accepted at BigMM 2023.
- Graduate Teaching Assistant @ (CSE 574) Machine Learning course at UB.
Summer 2023:
- 🎉 One Paper on Representation Learning, Explainability in Multimodal systems, accepted at ACM Multimedia 2023.
- Graduate Teaching Assistant @ (CSE 701) Sport Analysis using Computer Vision seminar.
Spring 2023:
- Submitted two papers to ACM Multimedia 2023.
- Graduate Teaching Assistant @ (CSE 560) Data Models and Query Languages course at UB.
Fall 2022:
- Submitted one paper to IJCAI 2023.
- Graduate Teaching Assistant @ (CSE 555) Introduction to Pattern Recognition at UB.
Research Publications
Adaptive Missing-Modality Emotion Recognition in Conversation via Joint Embedding Learning.

We propose AM\(^2\)-EmoJE, a model for Adaptive Missing-Modality Emotion Recognition in Conversation via Joint Embedding Learning model that is grounded on two-fold contributions: First, a query adaptive fusion that can automatically learn the relative importance of its mode-specific representations in a query-specific manner. Second, the multimodal joint embedding learning module that explicitly addresses various missing modality scenarios in test-time. By reporting around 2-5% improvement in the weighted-F1 score, the proposed multimodal joint embedding module facilitates an impressive performance gain in a variety of missing-modality query scenarios during test time.
Multi-label Emotion Analysis in Conversation via Multimodal Knowledge Distillation.
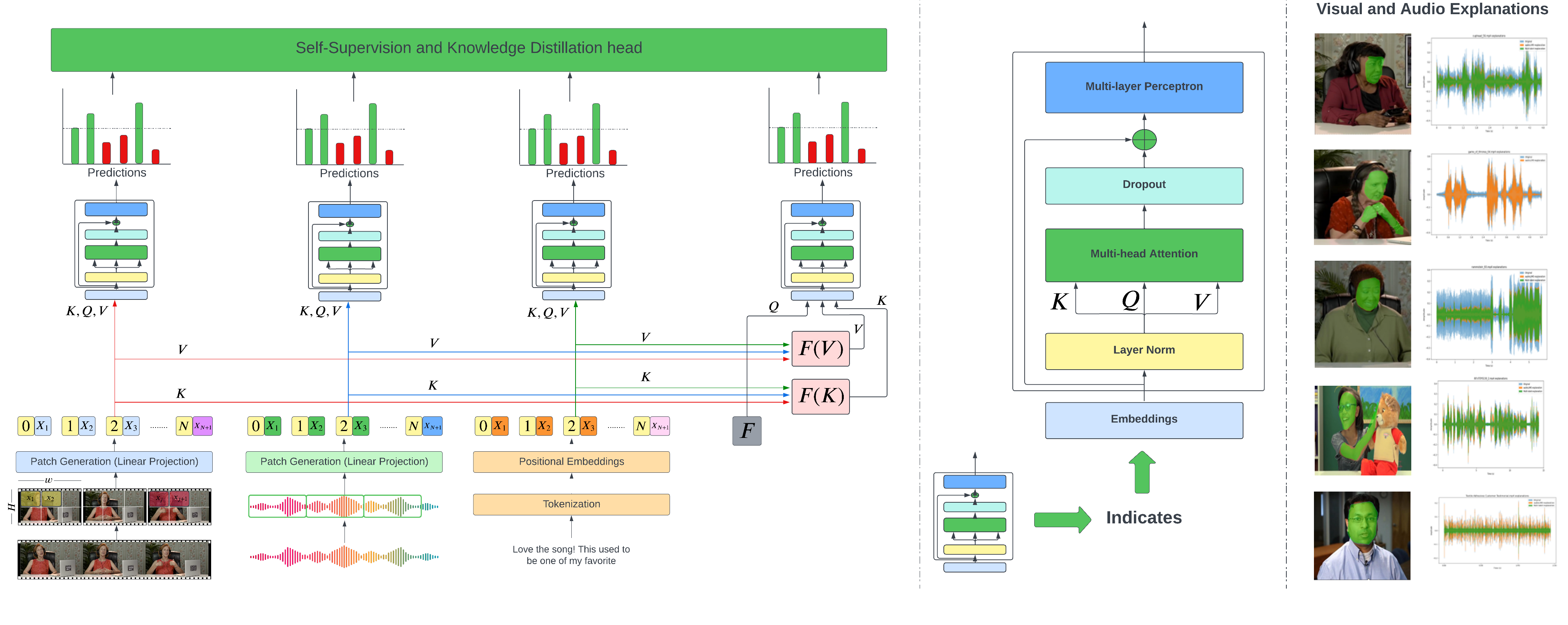
We present Self-supervised Multi-Label Peer Collaborative Distillation (SeMuL-PCD) Learning via an efficient Multimodal Transformer Network, in which complementary feedback from multiple mode-specific peer networks (e.g.transcript, audio, visual) are distilled into a single mode-ensembled fusion network for estimating multiple emotions simultaneously.
AMuSE: Adaptive Multimodal Analysis for Speaker Emotion Recognition in Group Conversations.
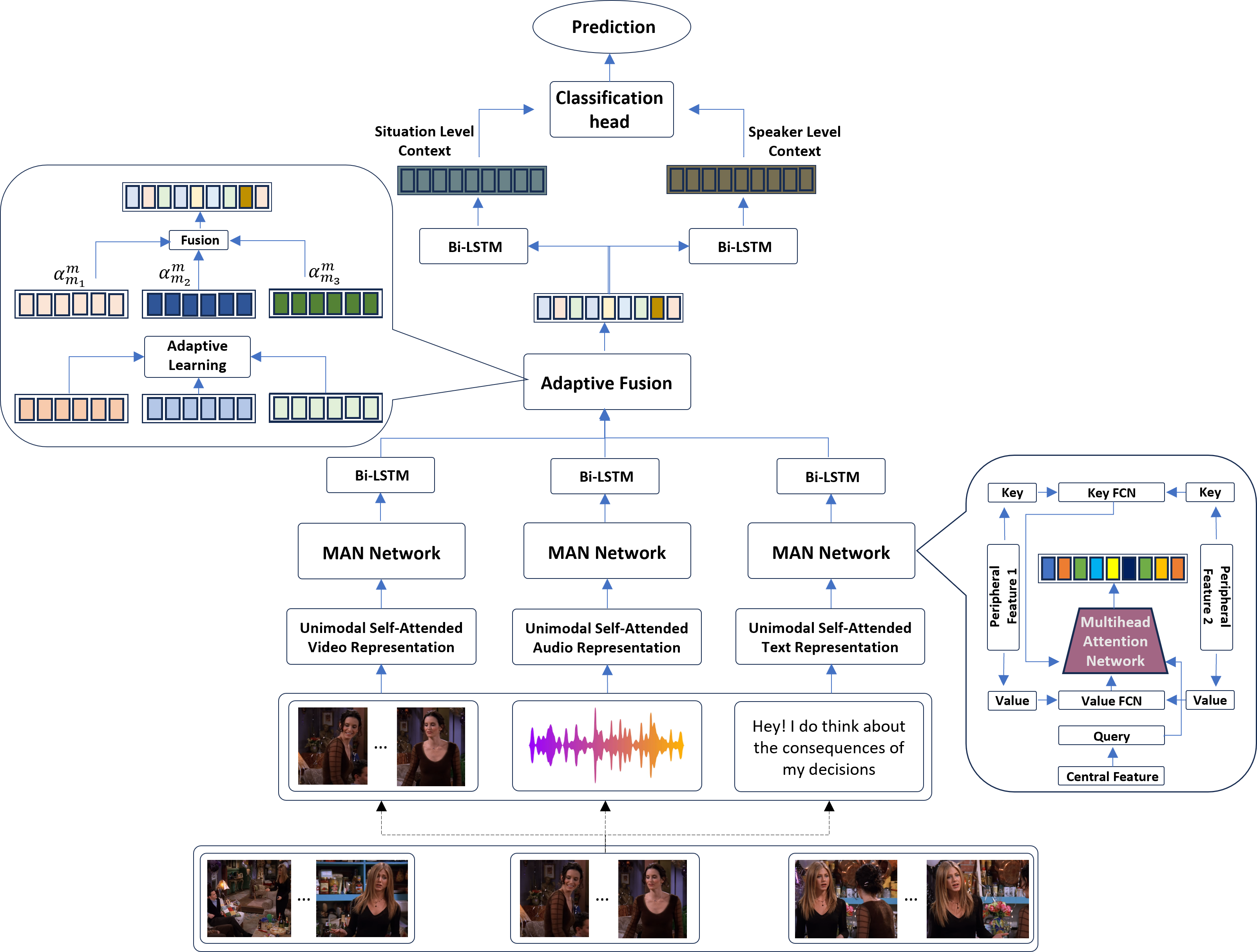
We propose a Multimodal Attention Network (MAN) that captures cross-modal interactions at various levels of spatial abstraction by jointly learning its interactive bunch of mode-specific Peripheral and Central networks. The proposed MAN “injects” cross-modal attention via its Peripheral key-value pairs within each layer of a mode-specific Central query network. The resulting cross-attended mode-specific descriptors are then combined using an Adaptive Fusion (AF) technique that enables the model to integrate the discriminative and complementary mode-specific data patterns within an instance-specific multimodal descriptor.
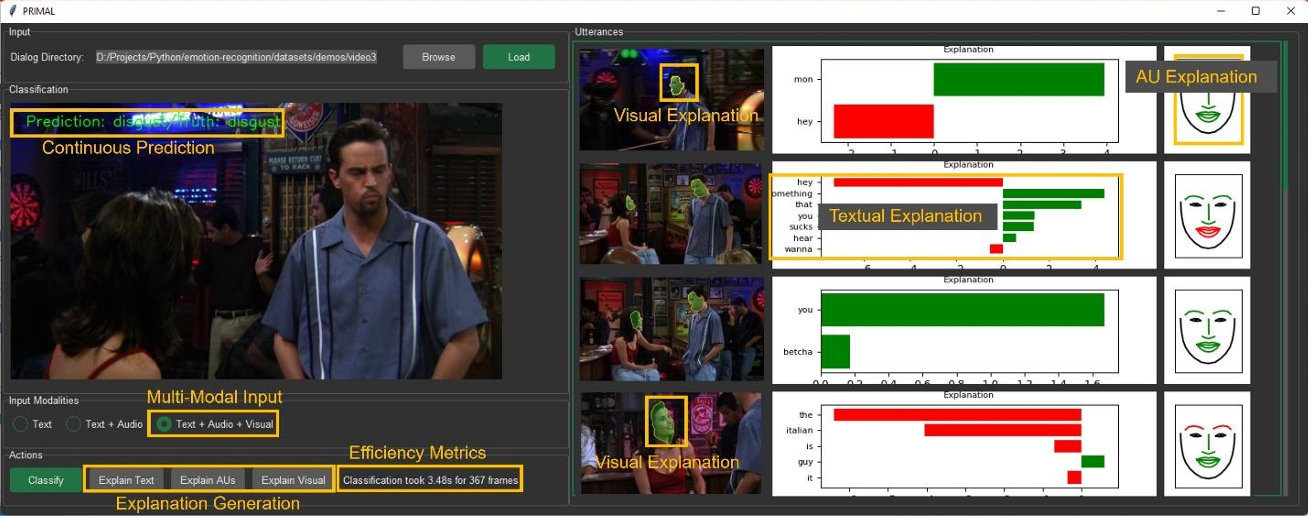
We propose a PRIvacy-preserving Multimodal Attentive Learning framework (PRIMAL) that derives the person-independent normalized facial Action-Unit based features to estimate the participants’ expression and keep track of their spatiotemporal states and conversation dynamics in the context of their surrounding environment to evaluate the speaker's emotion. By designing a novel contrastive loss-based optimization framework to capture the self- and cross-modal correlation within a learned descriptor, PRIMAL exhibits promise in accurately identifying the emotional state of an individual speaker in group conversations.
Academic Projects
Projects are done as a part of the courses at UB.